World models are emerging as a foundational paradigm for scalable, data-efficient embodied AI. In this work, we present GigaWorld-0, a unified world model framework designed explicitly as a data engine for Vision-Language-Action (VLA) learning. GigaWorld-0 integrates two synergistic components: GigaWorld-0-Video, which leverages large-scale video generation to produce diverse, texture-rich, and temporally coherent embodied sequences under fine-grained control of appearance, camera viewpoint, and action semantics; and GigaWorld-0-3D, which combines 3D generative modeling, 3D Gaussian Splatting reconstruction, physically differentiable system identification, and executable motion planning to ensure geometric consistency and physical realism. Their joint optimization enables the scalable synthesis of embodied interaction data that is visually compelling, spatially coherent, physically plausible, and instruction-aligned. Training at scale is made feasible through our efficient GigaTrain framework, which exploits FP8-precision and sparse attention to drastically reduce memory and compute requirements. We conduct comprehensive evaluations showing that GigaWorld-0 generates high-quality, diverse, and controllable data across multiple dimensions. Critically, VLA model (e.g., GigaBrain-0) trained on GigaWorld-0-generated data achieve strong real-world performance, significantly improving generalization and task success on physical robots without any real-world interaction during training.
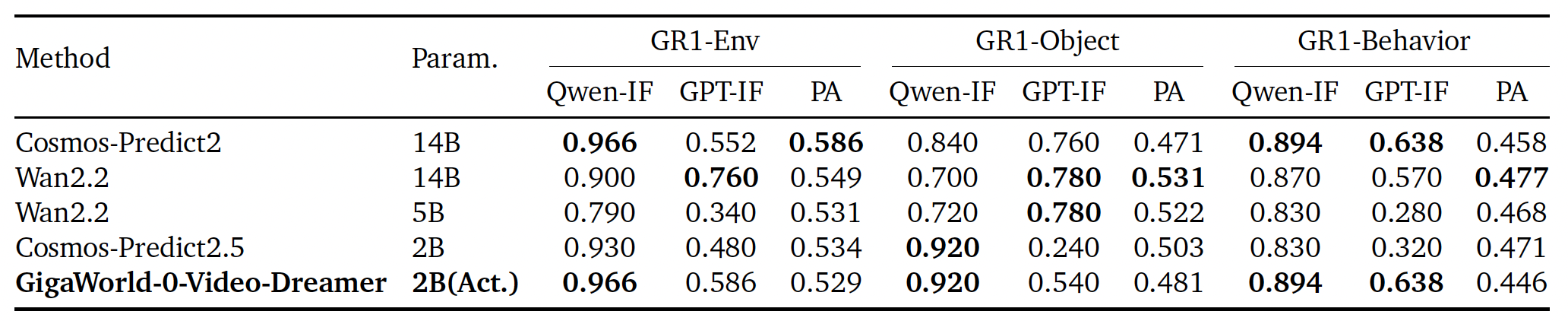
GigaWorld-0-Video-Dreamer employs sparse attention to significantly reduce computational overhead and memory footprint during long-horizon video prediction. Inspired by DeepSeek’s Mixture-of-Experts (MoE) architecture, it further incorporates a conditional sparsity mechanism that activates only a small subset of parameters per input, enabling more efficient modeling with fewer active parameters while preserving representational capacity.
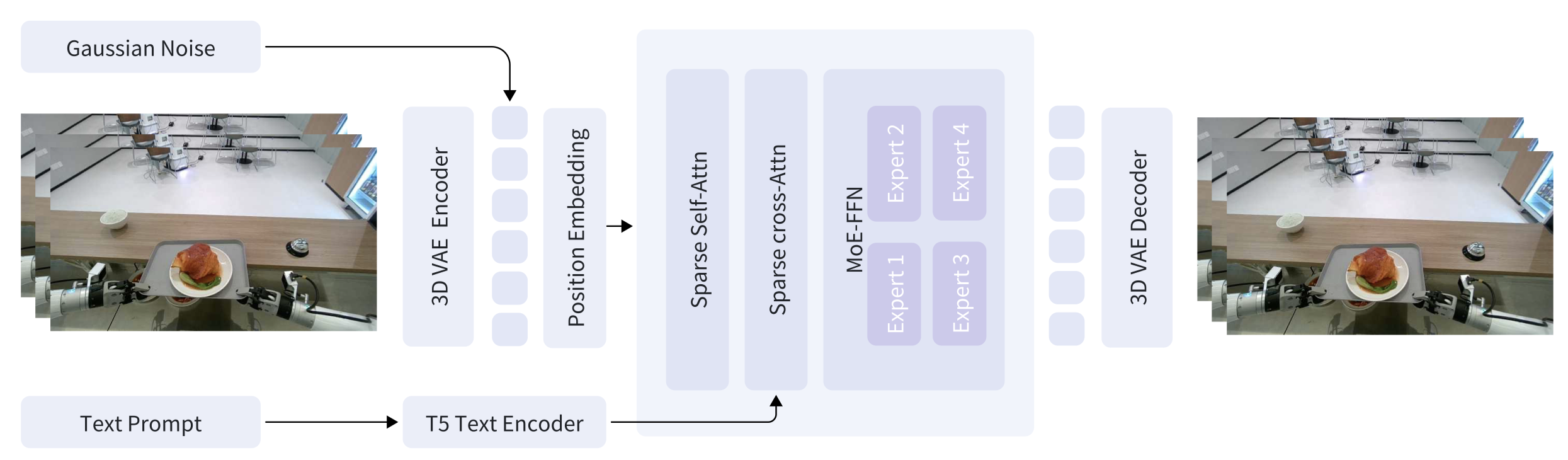
To enable efficient and cost-effective training, GigaWorld-0-Video-Dreamer adopts FP8-precision training. Our training infrastructure, GigaTrain, is a unified distributed framework designed for scalability and flexibility. It supports seamlessmulti-GPU/multi-node execution and integrates leading large-model training strategies, including: (1) Distribution framework: DeepSpeed ZeRO (Stages 0–3), FSDP2; (2) Mixed-precision training (FP16, BF16, FP8); (3) Gradient accumulation, gradient checkpointing, and exponential moving average (EMA); (4) Configurable optimizers, learning rate schedulers, and other training modules. This design enables both large-scale pretraining and resource-constrained post-training (e.g., fine-tuning with limited compute). To facilitate community adoption, we report resource consumption for various post-training configurations under modest hardware (e.g., 8×H20 GPUs with batch size 32), providing practical guidance for users seeking to adapt our model and framework for downstream embodied tasks.
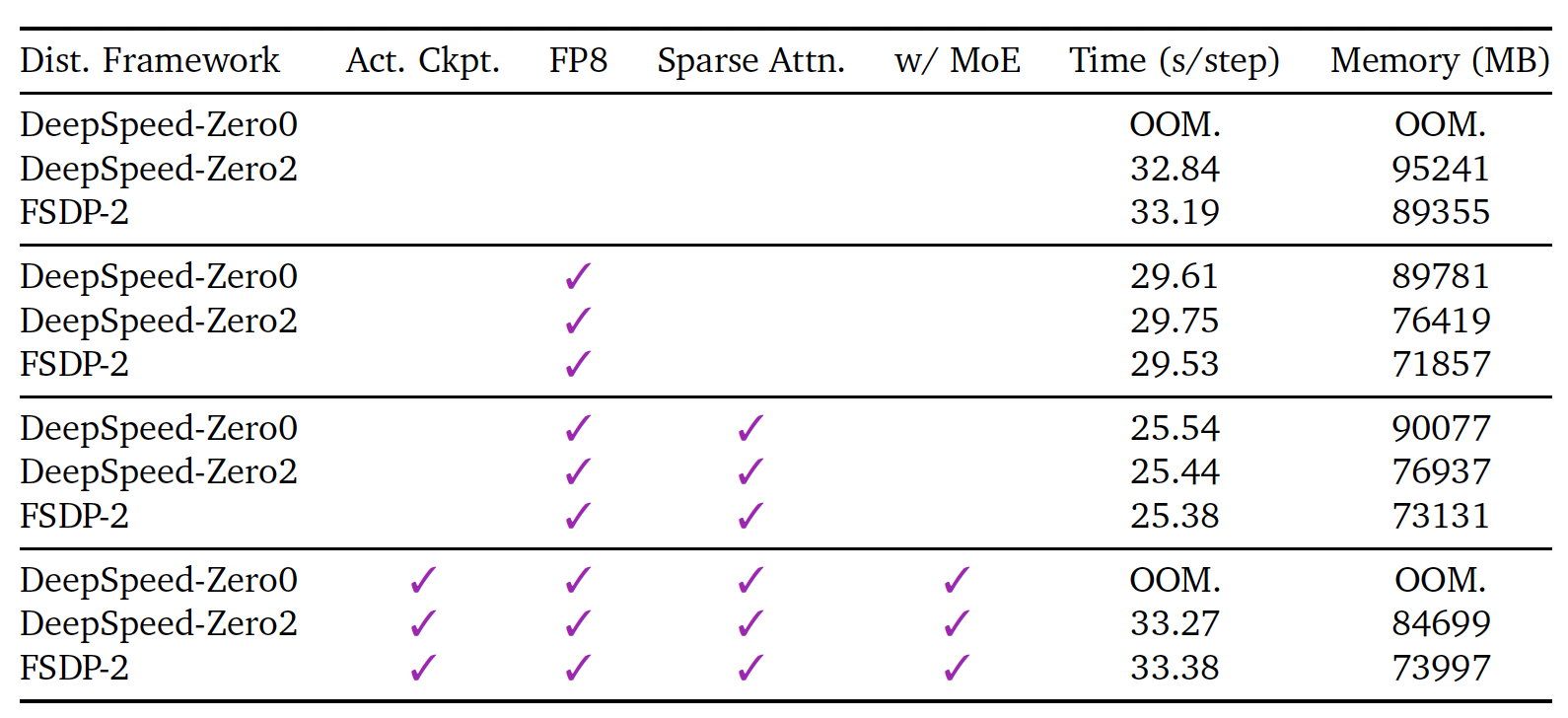
We compare GigaWorld-0-Video-Dreamer against recent state-of-the-art video generation models, including Cosmos-Predict2-14B, Cosmos-Predict2.5-2B, Wan2.2-5B, and Wan2.2-14B on the PBench (Robot Set) benchmark. Despite activating the fewest parameters (2B), our model achieves the highest overall score, highlighting its superior efficiency and generation quality for embodied AI tasks.
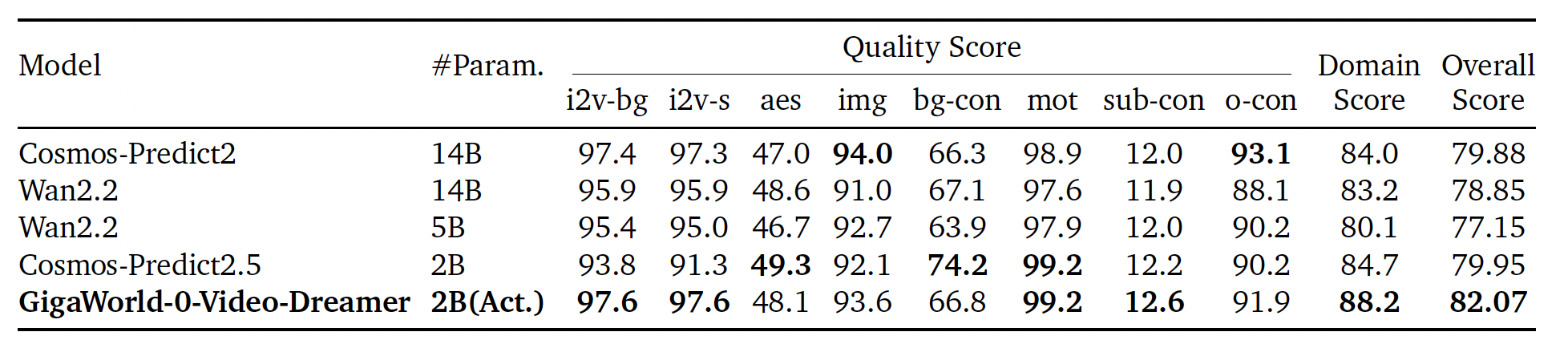
We evaluate all models on DreamGenBench using the publicly released GR1 robot dataset and strictly follow the official fine-tuning and evaluation protocol from DreamGen, including identical hyperparameters, prompts. Even without GR1-specific data in pretraining, GigaWorld-0-Video-Dreamer consistently surpasses the comparable Cosmos-Predict2.5-2B across all three GR1 scenarios, demonstrating stronger instruction-following fidelity and controllability in embodied manipulation.